The time of binders full of invoices and other documents is over. At least for me.
Almost all of my personal home office is paperless these days. However almost everything still arrives on paper. This article tells you how I deal with it.
The goal
My ultimate goal is to have as little paper documents as possible. A few things are too important to throw away, like important contracts or bank account credentials, but everything else should be stored digitally.
After looking at a few full blown document management solutions I switched to a very simple system: Storing the documents as PDFs in a regular folder structure.
The pipeline
Step one: Paper to PDF
I still get documents in paper by post.
So the first step is my scanner: An Epson WorkForce multi functional printer. The document scanner within the device has the nice functionality to directly store the scanned documents in the cloud.
My cloud storage provider is Google Drive, so when scanning a document it is automatically uploaded to the folder Inbox/Scanner/Raw in my Google Drive account.

Step two: Optimizing the PDF
The PDF generated by the Epson WorkForce isn’t really optimized yet (neither in terms of size nor in terms of content).
I found a nice little tool called OCRmyPDF which can enhance a scanned PDF so that not only the scanned image is contained inside it but also all text from that image via OCR - a nice addition for searching within a document and also an easy way to copy textual information out of a PDF. OCRmyPDF is also able to compress an image inside a PDF significantly, so that the resulting document not only contains the text but in addition is only about 60% of it’s original size.
So I want to run all PDF documents created by the scanner through OCRmyPDF.
As the name suggests the Raw folder is only an intermediary storage location designed for exactly this purpose: Have an inbox of PDFs that still need to be optimized.
Once the optimization is complete the PDFs should be moved to the Processed folder.
The following script applies OCRmyPDF and moves the optimized PDFs from the Raw folder to the Processed folder:
#!/usr/bin/env ruby
require 'fileutils'
require 'open3'
require 'shellwords'
original_file = ARGV.join(' ')
original_file_name = File.basename(original_file)
original_file_extension = File.extname(original_file_name.downcase)
target_file_name_without_extension = File.basename(original_file, File.extname(original_file))
target_file_extension = File.extname(original_file_name.downcase)
target_file_without_extension = File.join(File.expand_path(__dir__), "Processed/#{target_file_name_without_extension}")
target_file = "#{target_file_without_extension}#{target_file_extension}"
if original_file_extension == '.pdf'
puts "Converting PDF"
puts "- from: '#{original_file}'"
puts "- to: '#{target_file}'"
conversion_command = "PATH=\"/usr/local/bin:$PATH\" ocrmypdf -l deu -O3 --jbig2-lossy #{Shellwords.escape(original_file)} #{Shellwords.escape(target_file)} 2>&1"
conversion_stdout, _, conversion_status = Open3.capture3(conversion_command)
if conversion_status.exitstatus == 0
File.delete(original_file)
else
File.delete(target_file) if File.exist?(target_file)
File.write("#{target_file_without_extension}_conversionerror.txt", conversion_stdout)
FileUtils.mv(original_file, target_file)
end
else
puts "Moving regular file"
puts "- from: '#{original_file}'"
puts "- to: '#{target_file}'"
FileUtils.mv(original_file, target_file)
end
Step three: Automating the conversion
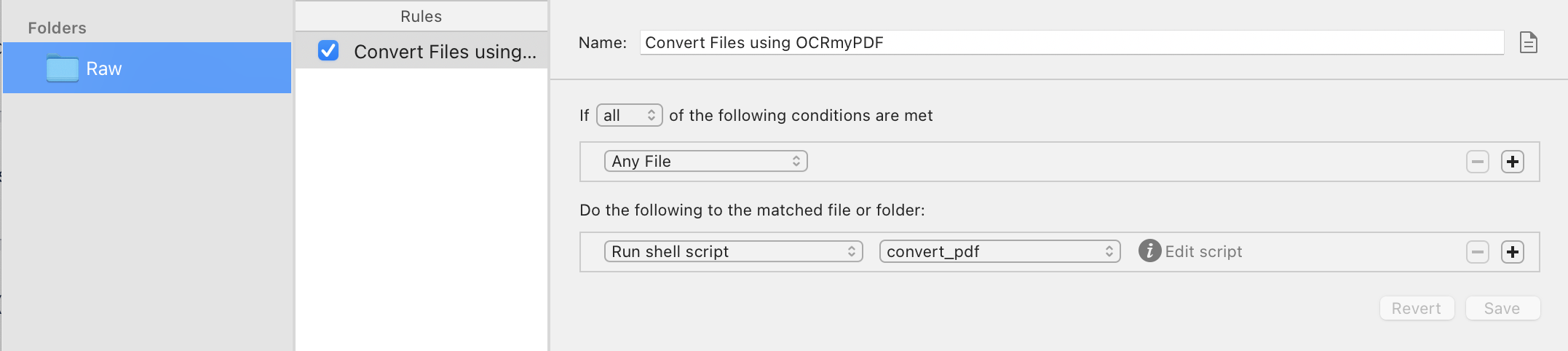
To make sure that the script is run automatically on each file that arrives in the Raw folder I use another little tool: Hazel.
Hazel runs silently in the background of my machine.
It is configured to listen to any changes made to the Raw directory and then invoke the script listed above for all files it detects.
Summary
Voila, the pipeline is complete:
- The scanner reads the document and stores in into Google Drive so it’s automatically synchronized to my local machine.
- Hazel detects new files and calls the conversion script.
- The conversion script optimizes the PDF and moves it into the target folder.
The only thing that is not yet automated is sorting the document into a target folder based on its content (e.g. invoices should be moved into the Invoices folder while documents from my health insurance should be moved into the Healthinsurance folder).
Nevertheless this eases a lot of my pain in managing my personal documents.